




By optimizing rewards-learning algorithms, DeepMind uncovered new details about how dopamine helps the brain learn.
In 1951, Marvin Minsky, then a student at Harvard, borrowed observations from animal behavior to try to design an intelligent machine. Drawing on ideas from the work of physiologist Ivan Pavlov, who famously used dogs to show how animals learn through punishments and rewards, Minsky created a computer that could continuously learn through similar reinforcement to solve a virtual maze.
by Karen Hao
At the time, neuroscientists had yet to figure out the mechanisms within the brain that allow animals to learn in this way. But Minsky was still able to loosely mimic the behavior, thereby advancing artificial intelligence. Several decades later, as reinforcement learning continued to mature, it in turn helped the field of neuroscience discover those mechanisms, feeding into a virtuous cycle of advancement between the two fields.
In a paper published in Nature today, DeepMind, Alphabet’s AI subsidiary, has once again used lessons from reinforcement learning to propose a new theory about the reward mechanisms within our brains. The hypothesis, supported by initial experimental findings, could not only improve our understanding of mental health and motivation. It could also validate the current direction of AI research toward building more human-like general intelligence.
At a high level, reinforcement learning follows the insight derived from Pavlov’s dogs: it’s possible to teach an agent to master complex, novel tasks through only positive and negative feedback. An algorithm begins learning an assigned task by randomly predicting which action might earn it a reward. It then takes the action, observes the real reward, and adjusts its prediction based on the margin of error. Over millions or even billions of trials, the algorithm’s prediction errors converge to zero, at which point it knows precisely which actions to take to maximize its reward and so complete its task.
It turns out the brain’s reward system works in much the same way—a discovery made in the 1990s, inspired by reinforcement-learning algorithms. When a human or animal is about to perform an action, its dopamine neurons make a prediction about the expected reward. Once the actual reward is received, they then fire off an amount of dopamine that corresponds to the prediction error. A better reward than expected triggers a strong dopamine release, while a worse reward than expected suppresses the chemical’s production. The dopamine, in other words, serves as a correction signal, telling the neurons to adjust their predictions until they converge to reality. The phenomenon, known as reward prediction error, works much like a reinforcement-learning algorithm.
DeepMind’s new paper builds on the tight connection between these natural and artificial learning mechanisms. In 2017, its researchers introduced an improved reinforcement-learning algorithm that has since unlocked increasingly impressive performance on various tasks. They now believe this new method could offer an even more precise explanation of how dopamine neurons work in the brain.
Specifically, the improved algorithm changes the way it predicts rewards. Whereas the old approach estimated rewards as a single number—meant to equal the average expected outcome—the new approach represents them more accurately as a distribution. (Think for a moment about a slot machine: you can either win or lose following some distribution. But in no instance would you ever receive the average expected outcome.)
The modification lends itself to a new hypothesis: Do dopamine neurons also predict rewards in the same distributional way?
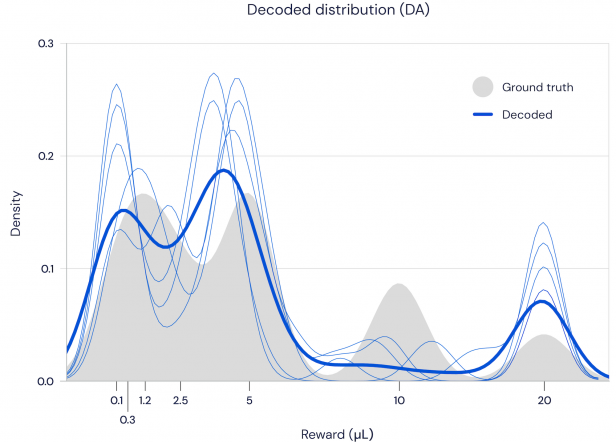
To test this theory, DeepMind partnered with a group at Harvard to observe dopamine neuron behavior in mice. They set the mice on a task and rewarded them based on the roll of dice, measuring the firing patterns of their dopamine neurons throughout. They found that every neuron released different amounts of dopamine, meaning they had all predicted different outcomes. While some were too “optimistic,” predicting higher rewards than actually received, others were more “pessimistic,” lowballing the reality. When the researchers mapped out the distribution of those predictions, it closely followed the distribution of the actual rewards. This data offers compelling evidence that the brain indeed uses distributional reward predictions to strengthen its learning algorithm.
“This is a nice extension to the notion of dopamine coding of reward prediction error,” wrote Wolfram Schultz, a pioneer in dopamine neuron behavior who wasn’t involved in the study, in an email. “It is amazing how this very simple dopamine response predictably follows intuitive patterns of basic biological learning processes that are now becoming a component of AI.”
The study has implications for both AI and neuroscience. First, it validates distributional reinforcement learning as a promising path to more advanced AI capabilities. “If the brain is using it, it’s probably a good idea,” said Matt Botvinick, DeepMind’s director of neuroscience research and one of the lead authors on the paper, during a press briefing. “It tells us that this is a computational technique that can scale in real-world situations. It’s going to fit well with other computational processes.”
Second, it could offer an important update to one of the canonical theories in neuroscience about reward systems in the brain, which in turn could improve our understanding of everything from motivation to mental health. What might it mean, for example, to have “pessimistic” and “optimistic” dopamine neurons? If the brain selectively listened to only one or the other, could it lead to chemical imbalances and induce depression?
Fundamentally, by further decoding processes in the brain, the results also shed light on what creates human intelligence. “It gives us a new perspective on what’s going on in our brains during everyday life,” Botvinick said.
This article originally appeared in MIT Technology Review. Photo by Alina Grubnyak on Unsplash.






